Search is becoming increasingly conversational in nature, and the growth of mobile in search is only perpetuating this trend (and the technology that powers it). This shift in search is fundamentally changing how content is discovered, crawled, indexed, understood, and ranked. To understand where SEO is going next, it’s important to understand some of the underlying changes in how search works and how we can take advantage of it.
Understanding Language
There has been a significant improvement in search engines’ ability to read and understand written and spoken text. This includes both queries provided by users and indexable content like articles and tweets.
There are four primary parts to breaking down strings of text:
- Tokenization
- Parts of speech tagging
- Lemmatization
- Named entity detection
#1 Tokenization
Tokenization is the process of breaking strings down into individual tokens of words and phrases. These tokens can be classified and have meaning applied to them.
The phrase “who directed Pulp Fiction” could have 3 tokens – 1) who 2) directed 3) Pulp Fiction.
#2 Parts of speech tagging
Parts of speech tagging is the process of classifying tokens based on their meaning within a particular language. To understand this, think back to grade school when you had to diagram sentences on the board, breaking out nouns, verbs, subjects, and predicates.

The sentence above has its tokens broken down into three different parts of speech, represented by two or three letter acronyms. At this level of categorization, search engines not only know a word, but they understand its role within the language. This understanding can help them connect relations and determine how to use the keyword phrase. A full list of POS tags can be found here.
#3 Lemmatization
There are many ways to say the same thing in a single language. Lemmatization simplifies this by converting multiple words to a single word when several words effectively share the same mean. Think of this as converting words to their canonical word.
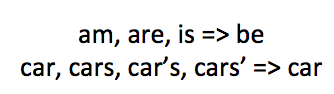
#4 Named entity detection
Named entity detection is taking POS tagging one step further and determining when a word or phrase has meaning in the the real world. Knowledge graphs assist this process and it is a key part of entity search.

Query the Knowledge Graph
Once strings are broken down, accessing “knowledge” about entities becomes relatively simple. The Knowledge Graph in Google can be effectively replicated allowing access to this data for content evaluation, keyword targeting, and internal linking. It provides an exceptionally valuable data source for anyone creating content around entities.
Using a little scripting, we can replicate Google’s ability to do this.
We can replicate this using a language called MQL (Metaweb Query Language; rhymes with “pickle”), which is an API for making programmatic queries to Freebase.
A request can be sent using this URL:
https://www.googleapis.com/freebases/v1/mqlread?query={<insert query here>}
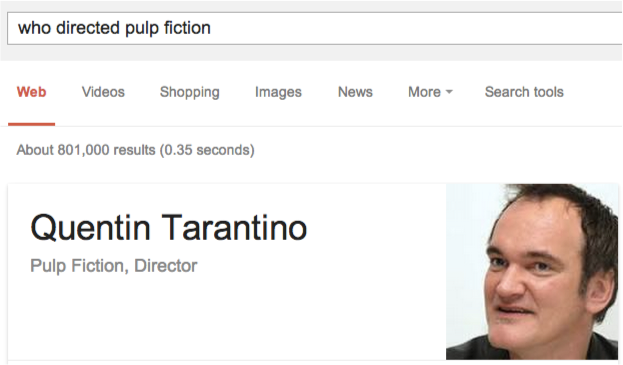
Using Natural Language Processing (NLP) we can convert strings into structured queries.
For example, we can break down the question “Who directed Pulp Fiction”:
[{
"!/film/film/directed_by": [{
"/type/object/name": "pulp fiction",
"/type/object/type": "/film/film"
}],
"/type/object/name": [{}],
"/type/object/type": "/people/person"
}]
Through NLP, a string can be broken down and placed logically into a structured query. Once passed to Freebase, it replies with a structured response that contains the answer to the question.
{
"result": [
{
"!/film/film/directed_by": [
{
"/type/object/type": "/film/film",
"/type/object/name": "Pulp Fiction"
}
],
"/type/object/type": "/people/person",
"/type/object/name": [
{
"lang": "/lang/en",
"type": "/type/text",
"value": "Quentin Tarantino"
}
Inside of this response, there is the answer – Quentin Taratino.
Quick & Easy Using Quepy
For those intimidated by this process, there is a nifty tool called Quepy, which is a Python based tool for generating queries to be ran in the DBpedia database or the Freebase database. You simply ask it a question in natural language and it will spit out the script to run in Freebase (you can also check out the Freebase query editor).
Asking Questions for Content
With Quepy and MQL in hand, we can start to ask questions of increasing complexity. These answers provide a wide range of possibilities in terms of content writing, targeting, internal links, and content organization.
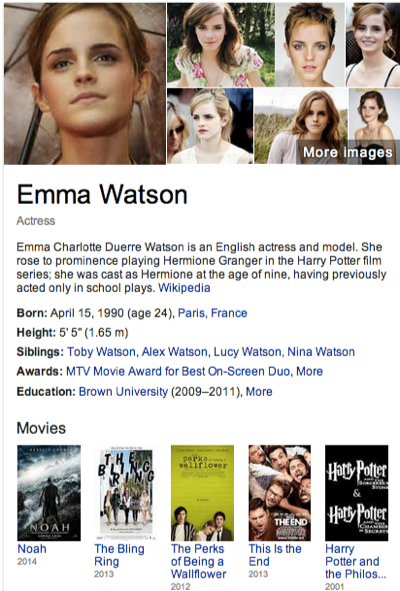
For example, you could programmatically ask: “What movies did Emma Watson star in?”:
[{
"type": "/film/film",
"only:starring": {
"actor": {
"name": "Emma Watson"
}
},
"name": null,
"imdb_id": []
}]
This would pull back a list of Emma Watson’s movies, their titles, and IMDB pages. You can replicate this process for other actors and actresses fairly easily. (We’ll come back to why this is great and how to use it later).
Implicit Entities in Search
In search today, THINGS matter and these things are called entities, which Google has become increasingly better at identifying both in queries as well as content. It’s important to understand that entities are not just referenced explicitly in a way that can be identified with Named Entity Detection, but they’re also referenced implicitly. For example, “photos of Big Ben” is an explicit query, while “that big clock in London” is a corresponding implicit query.
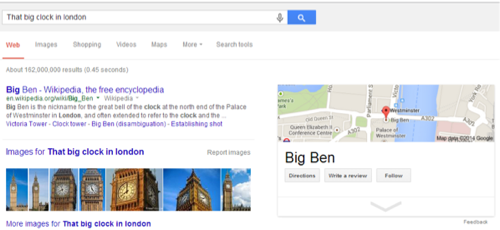
Implicit entity queries, or implicit entity text strings in articles, occur when a known thing is referenced using commonly understood attributes, but without directly mentioning its name or another unique identify feature (like an address or ID number). Google is already fairly good at this, even in cases where it’s less obvious.
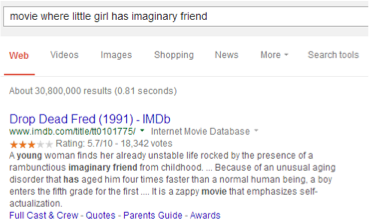
In the example above, Google accurately determines the query is implicitly referring to a lesser known movie, Drop Dead Fred.
Entity Search as a Vertical Appearing in Blended Results
Entity search’s impact is obvious when it triggers a carousel or knowledge graph, but entities and natural language processing is playing a larger role in universal search, where it is blended into results in a manner similar to how local, image, or news results are blended when it’s relevant. Both implicit and explicit queries can trigger the entity vertical, where the results are identified as relevant to the entity then blended into the general results before being returned to the user. This provides a new opportunity and approach to rank, especially in the longtail of implicit entity searches.
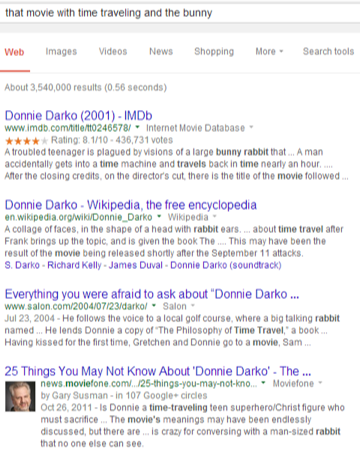
Entities provide an opportunity to rank in traditional results when the entity has been determined as the intent of the query. In the example above, Google is able to accurately identify this as an implicit reference to the movie Donnie Darko, pulling in relevant articles through traditional search. Think beyond the basic presentation layers of entity search, like knowledge panel, answer boxes, and carousels. These are much harder to leverage for direct traffic value. The blended visibility, however, is how we can leverage entities to drive incremental traffic from search.
Expanding to Capability Search
Entities are just one part of the puzzle of the ever expanding scope of search. In the last few years, search has fundamentally changed the paradigm of how SEO works, because it changed what search engines index and how they retrieve answers.
Historically, search lived in the web and was for the web. It would index a document and return those documents based on increasingly complex information retrieval algorithms that all inherently relied on some form of keyword relevancy and backlinks. This is the primary means of web document search, but search has expanded well beyond this paradigm.
Today, search has been elevated outside of the web and instead searches against different capability types. Of these, one is traditional web document search.
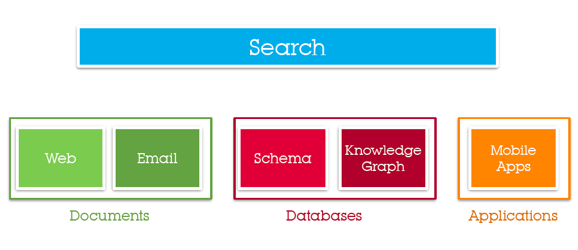
In this view of search, web documents are not the only type of content that is indexed and searched against. Capability search might include documents, like web pages, and increasingly more personal content, like emails and social media. But beyond that, search now includes data like Schema (turning webpages into databases) and Knowledge Graph (Freebase, DBpedia, and Google’s understanding of the world). The most interesting development in Capability search is application (e.g., Mobile Apps) indexation and search which allow Google to not only return pages, or even answers, but execute behavior / actions. Search can interact with programs by combining natural language, the knowledge graph, and app functionality.
Examples of capability searches:
- What is Limburger – This is a basic Knowledge Graph search, where the result is not necessarily a web page, but an answer, which can be solved with an Answer Box or verbal text to speech result.
- Play say it ain’t so – The intent here isn’t to look at text at all. Instead, the intent is to open an app and play a song.
- Schedule a meeting with Lynn – The intent here is to take an action, which might require a search of personal data like email or contacts to identify Lynn as a known entity to me personally. The result is opening an email or calendar invite to send the meeting request.
- Navigate to grandma’s house – Using personal data, local, and maps Google could answer this query by driving a car.
The greatest, scariest, yet most exciting thing about these queries is that they never touch the web in the traditional sense and their answers don’t come from the web either. There is little to nothing traditional SEO can do to influence these search results.
This starts to opening a whole realm of new strategies and tactics for SEO. So far, I think we’re only scratching the surface of search and the role SEO will play in its future.
While the future is exciting, let’s jump right in on what we can do today to start taking advantage and to be prepared for where search is going next. First, we’ll look at how application indexing and actions function, then we’ll look how Google is using personal data like email to push search results via Google Now, and lastly we’ll end with looking at how to leverage this in traditional SEO and content optimization.
Leveraging Mobile App Indexation
Crawl, indexing, and ranking is no longer restricted to web documents. Recently, by leveraging deep linking, apps have become indexable. This allows search engines to show app in search results, opening content in app instead a browser, and allows search engines to execute actions, like playing a song in an app.
App Actions Through App Indexation
Interacting with apps through search starts with app indexation, which is the process of defining deep links in an app, which define deep sections of an app that can be opened using a URI. These app URIs can be indexed by search engines (for Android apps).
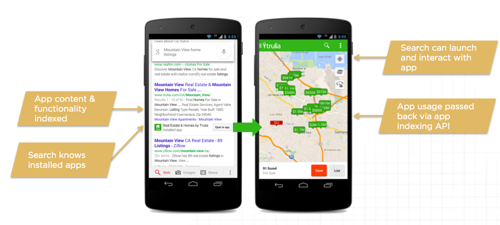
Creating an app that is indexable is a relatively simple but new tactic. With the on-going expansion of app specific optimization, I expect the umbrella of technical SEO to grow to increasingly include tactics outside of traditional server setup and web page optimization.
#1 App URL Format & Deep Linking
To get started, it’s important to understand the difference between web and app URI formats. This following URL can inform a particular app to open and the host_path is passed into the app. The app is then setup to understand how handle the app URL.
android-app://{package_id}/{scheme}/{host_path}
- package_id – app ID in Play store
- scheme – http or custom scheme
- host_path – specific content within app
To setup deep linking, you’ll want to make the following changes to your AndroidManifest.xml file:
<activity android:name="com.example.android.GizmosActivity" android:label="@string/title_gizmos" > <intent-filter android:label="@string/filter_title_viewgizmos"> <action android:name="android.intent.action.VIEW" /> <!-- Accepts URIs that begin with "http://example.com/gizmos” --> <data android:scheme="http" android:host="example.com" android:pathPrefix="/gizmos" /> <category android:name="android.intent.category.DEFAULT" /> <category android:name="android.intent.category.BROWSABLE" /> </intent-filter> </activity>
AndroidManifest.xml changes explained:
- Add an <intent-filter> element for activities that should be launch able from Google Search
- Add an <action> tag, which specifies the ACTION_VIEW intent action. This means to display the data to the user. This is the most common action performed on data.
- Add a <data> tag for each data URI format the activity accepts. This is where the format of the URI (deep link) is declared, including the scheme http or custom, the host, and the prefix.
- Add a <category> for both BROWSABLE and DEFAULT intent categories.
- BROWSABLE is required in order for the intent to be executable from a web browser. Without it, clicking a link in a browser cannot resolve to your app and only the current web browser will respond to the URL.
- DEFAULT is not required if your only interest is providing deep links to your app from Google Search results. However, the DEFAULT category is required if you want your Android app to respond when users click links from any other web page that points to your web site.
#2 Connect Webpage to App with JSON-LD & Rel=Alternate
Next up, we want to add the deep link to the website, allowing Google to relate the webpage URL to the mobile URI. This is very similar to mobile site optimization where an alternative mobile URL is defined for a given page on the website. To do this, we want to use JSON-LD.
JSON-LD is a lightweight Linked Data format based on JSON. It allows Schema.org markup to be defined in JSON instead of microdata. It is supported by Schema.org and Google.
To make the connection between website and app, we’ll want to use the Schema.org ViewAction:
<script type="application/ld+json"> { "@context": "http://schema.org", "@type": "WebPage", "@id": "http://example.com/gizmos", "potentialAction": { "@type": "ViewAction", "target": "android-app://com.example.android/http/example.com/gizmos" } } </script>
This connection can also be defined using Link Rel=Alternate in both the HTML head and the XML sitemap.
<link rel="alternate" href="android-app://com.example.android/http/example.com/gizmos" />
As Googlebot crawls a site, they discover the corresponding mobile app URI, allowing it to be indexed along with the desktop and mobile version of an app.
#3 App Indexing API
In addition to exposing app URI via traditional webpages, Google can discover content in the app via their App Indexing API.
The App Indexing API provides a way for apps to notify Google about deep links. Basically, as user engages with an app, the URIs are passed to Google. These URIs, and the app in general, become available in Google Search query auto-completion, which surfaces the app and inner “pages’ in the app. This helps drive re-engagement through Google Search.
#4 Robots Noindex for Apps
Once an app is indexable, there may be content and areas of the app that you’d like to keep out of the app. For this, there is effectively a meta robots noindex for app URIs.
To block app URIs, add the following to the app resource directory: res/xml/noindex.xml
<?xml version="1.0" encoding="utf-8"?> <search-engine xmlns:android="http://schemas.android.com/apk/res/android"> <noindex uri="http://example.com/gizmos/hidden_uri"/> <noindex uriPrefix="http://example.com/gizmos/hidden_prefix"/> <noindex uri="gizmos://hidden_path"/> <noindex uriPrefix="gizmos://hidden_prefix"/> </search-engine>
This can block specific URI and prefixes from being indexable via app indexing. Once this update is made, the AndroidManifest.XML file should be updated to reference this noindex.xml file.
<manifest xmlns:android="http://schemas.android.com/apk/res/android" package="com.example.android.Gizmos"> <application> <activity android:name="com.example.android.GizmosActivity" android:label="@string/title_gizmos" > <intent-filter android:label="@string/filter_title_viewgizmos"> <action android:name="android.intent.action.VIEW"/> ... </activity> <meta-data android:name="search-engine" android:resource="@xml/noindex"/> </application> <uses-permission android:name="android.permission.INTERNET"/> </manifest>
With these basic changes in place, an app should be setup to allow for indexation and more advanced features like app actions.
Leveraging App Actions
App actions take app indexing a step further, allowing search engines to understand and execute behavior inside of the app. In the examples above of playing a song, emailing a person, or driving a car, could be achieved through the use of app actions. Google is already supporting the song example.
 App actions come from connecting deep links in an app to an understanding of the real world based off the knowledge graph. This allows Google to understand that “Say it ain’t so” is a song, that a song can be heard, and that a particular app has that song.
App actions come from connecting deep links in an app to an understanding of the real world based off the knowledge graph. This allows Google to understand that “Say it ain’t so” is a song, that a song can be heard, and that a particular app has that song.
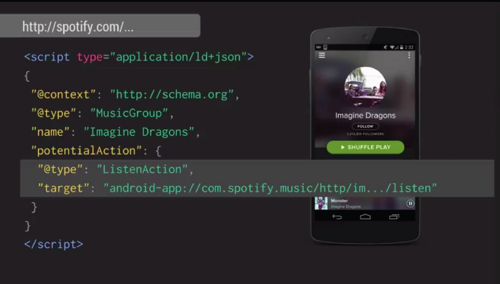
To set this up, an app action can be defined using JSON-LD. In the example above, the ListenAction in Schema.org is used to define the relationship between a known entity and a listen action in the app, which is represented as a deep link URL. In this example, the app is setup to understand this URL and execute the play action inside the app.
Opportunities for App Indexing
Currently, there are four different ways your apps can gain visibility in organic search.
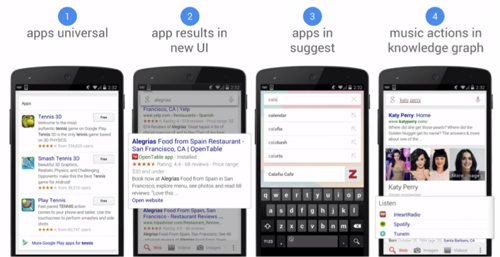
While the current examples are limited and the use cases restricted, app indexation opens the door to an exceptionally sophisticated search, that not only understands text, but can take actions on our behalf.
Integrating Personal Data & Pushed Results
As search is becoming more conversational, it’s also becoming more personal. This elevation beyond webpages is allowing search engines to look broadly at personal data, including email, usage, location, and history.
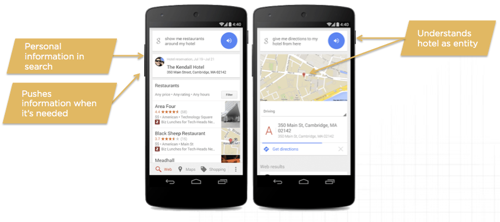
In the example above, search is supplemented with additional data that understands the user has a hotel reservation and understands that hotel as an entity. The user can use natural language like “my hotel” to reference the hotel as a known entity. In additional to customizing the results based off knowledge about the reservation, it actively pushes information into the search result based off these user’s location (pushing in additional data about the hotel reservation).
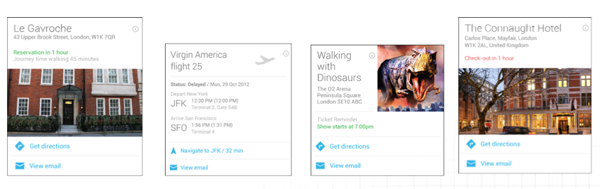
Through Google Now, there of a number of cards that get pushed into search results based off of personal data. These include topic ares like hotels, dinner reservations, events, and flights. When combined with mobile search, Google can increasingly push search results to users, and when combined with conversational search, Google can have increased context to answer questions and execute tasks based of a user’s day-to-day life.
Google Indexing Email Content
This personal data comes from indexing email content. You’ve likely seen these summary boxes in Gmail.
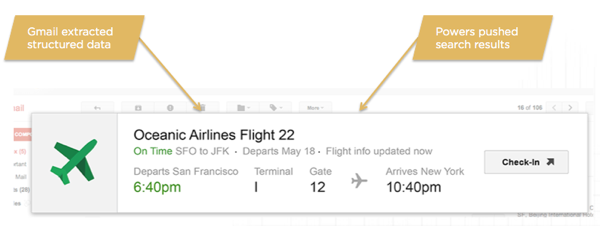
These are created by Gmail extracting data from emails, particularly when it’s structured, allowing them to create the call outs at the top of email. This process is what is powering these pushed search results above. This is how Google understood the user’s hotel reservation in the earlier example, allowing them to understand the phrase “my hotel” as a specific entity. This can also give Google context on travel behavior and future location data.
Pushing Data into Google Now with Structured Data
Marking up email content with Schema.org allows Google to better understand emails and integrate that knowledge into their search results, as well as leverage that data in Google Now to push data to users. When sending emails to customers, think about how the content can be marked up. This includes transactional emails like receipts and confirmations, especially when the email is time or location oriented.
We can trigger events using Actions in the Inbox. This can be tested on any Gmail account by sending an email to yourself. For example, I can email myself a fake hotel reservation for a fake hotel in San Francisco, and Google Now will start to show weather cards for San Francisco, even though I’m still in Seattle.
Making this content indexable is fairly straight-forward. Actions in the Inbox can be leverage by using traditional Schema.org in emails. Here is an example of marking up an event registration.
<div itemscope itemtype="http://schema.org/EventReservation"> <meta itemprop="reservationNumber" content="E123456789"/> <link itemprop="reservationStatus" href="http://schema.org/Confirmed"/> <div itemprop="underName" itemscope itemtype="http://schema.org/Person"> <meta itemprop="name" content="John Smith"/> </div> <div itemprop="reservationFor" itemscope itemtype="http://schema.org/Event"> <meta itemprop="name" content="Foo Fighters Concert"/> <meta itemprop="startDate" content="2017-03-06T19:30:00-08:00"/> <div itemprop="location" itemscope itemtype="http://schema.org/Place"> <meta itemprop="name" content="AT&T Park"/> <div itemprop="address" itemscope itemtype="http://schema.org/PostalAddress"> <meta itemprop="streetAddress" content="24 Willie Mays Plaza"/> <meta itemprop="addressLocality" content="San Francisco"/> <meta itemprop="addressRegion" content="CA"/> <meta itemprop="postalCode" content="94107"/> <meta itemprop="addressCountry" content="US"/> </div> </div> </div>
You can test this by sending an email to yourself (from [email protected] to [email protected]), and the data will be displayed across Google products. However, you’ll need to register with Google for your data to appear more broadly. Google even provides a step-by-step tutorial to test sending yourself an email via App Scripts.
This is how you get personalized, life aware, entity centric conversational search results like the one below. Because of this, a user can ask “restaurants near my hotel” and be understood – giving businesses a new way to get visibility in organic search.
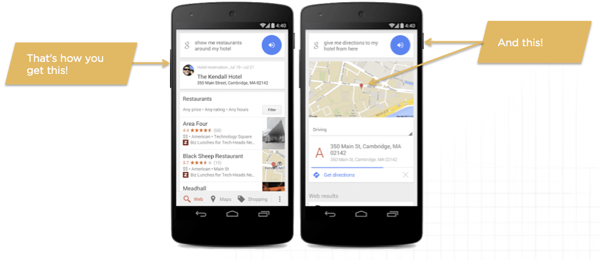
Targeting Conversational Search with Traditional SEO
The expansion to indexable apps and databases is exciting, but there are a variety of tactics available in traditional search to target the expansion into conversational search and entities.
Use Schema.org with Page Content
First and foremost, make sure you’re taking care of the basics and mark-up your content with Schema.org. Schema takes you from web pages to data, effectively turning your website into a database that search engines can query, similar to how we queried MQL earlier. Check out JSON-LD for marking up pages in JSON-LD instead of inline. Also, keep an eye on Schema.org’s blog, which helps give insight into how structured data for search is being developed.
Effectively Use Sentence Structure to Define Relationships.
By combining an understanding of natural language processing with the concepts of triples, content can be written in a way that clearly defines a relationship.
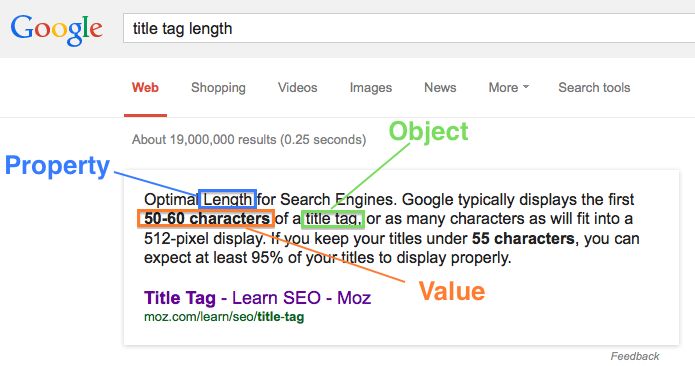
In the example above, the sentence structure clearly defines a relationship. Google understands that “title tag” as a token that has known meaning in some verticals as a HTML element and can leverage NLP to build a triple out of the sentence.
This may radically change how link building works as natural language brand mentions can create implicit citations / backlinks. For example, in a sentence like “Getty Images has great photos of Brad Pitt”, NLP processing can be used to to turn this into a link.
- Getty Images – Known entity, company, has a website (HREF)
- Has – Verb, defining the relationship (anchor tag)
- Photos – Noun (anchor text)
- Brad Pitt – Known entity, the kind of photos (anchor text)
- Great – Adjective, sentiment
Find Frequently Searched Attributes
To bring this all together, we want to look for ways where we can create content that accomplishes one of these three goals:
- Targets the entity directly, to rank in explicit entity search results.
- Targets questions about entities where the user directly asks about an attribute an entity has.
- Targets longtail implicit entity search terms, where the answer to the query is an entity, but the query doesn’t directly address the entity.
A quick hack to find opportunities for #2 and #3, which you can leverage when building triples in content, is to use auto suggest via a tool like Ubersuggest.
Finding Popular Entity Attributes
1) Identify a few example entities
Brainstorm a few popular entities of a particular entity type. For example, for NFL quarter backs we might look at Russell Wilson & Peyton Manning.
2) Search question words along with entity name in Ubersuggest
Perform a search with your example entities paired with question words (who, what, when, etc.). Scrape these and put into a spreadsheet / database.

3) Consolidate, clean and count
Take the results across multiple examples and clean up the queries, removing the entities name (russel willson) and other the question phrases (what’s, what is). Once this is done, use a pivot table to count the frequency of occurrence. This will help identify the most popular attributes.
For example, for a NFL quarterback, people might want to know the answers to questions like:
- How fast do they run the 40
- What is their net worth
- Where did they go to college
- What is their jersey number
- What is their salary
4) Integrate answers to popular attributes into content
With this insight, we can start to appear in implicit queries centered around the entity and their most popular attributes that might trigger an implicit entity result. Using very clear sentence structure and an understanding of NLP, a copywriter can clearly articulate a triple that answers these attribute questions. Lastly, we can use this data programmatically at scale by integrating it with MQL pulls to dynamically target content, but more on that in a moment.
Build Capsule Pages Dedicated to Entities
While not a broadly applicable tactic, creating dedicated, curated, and robust experiences for an entity is a great tactic for the sites with the product and content to do so. We can make exceptional landing pages that can rank for a wide range of implicit entity search queries.
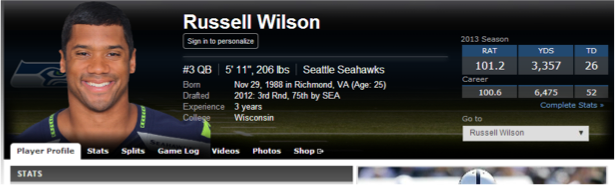
These pages can be build in a very effective manner by taking unique data and content and expanding it using the popular entity attribute approach above with MQL to supplement content using Freebase. At scale, this can become very powerful.
Disambiguate Entities
This understanding of popular attributes can also help to disambiguate entities when there is confusion. For example, there are two Brad Pitts, a famous actor and olympic boxer. Traditional keyword targeting practices are not effective in targeting either Brad Pitt to the correct entity association.

By leveraging popular attributes in copy, a page can be better aligned to disambiguate entities. By leveraging keywords with a high co-occurance with the named entity, a copywriter can improve the likelihood that an article will appear in implicit search queries associated with that entity.
Dynamic Title Tag Targeting
Going back to our capsule style page example earlier, we can go beyond just on-page content and use linked data to dynamically power keyword targeting via the HTML title element.
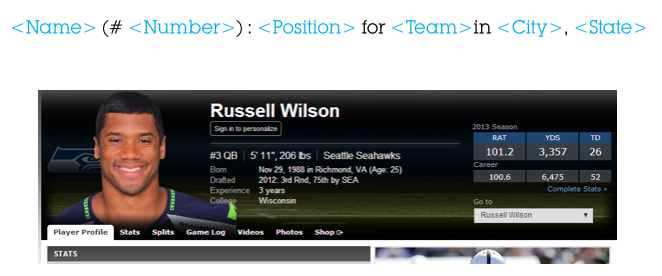
We can query Freebase using MQL to dynamically popular HTML titles using these most popular attributes. This will further increase the page’s likelihood to appear in implicit entity results.
You can permutate this approach in several ways, such as categorical title tag schemes to dynamically change your keyword targeting approach. This is exceptionally useful for sites that function at scale with a high number of URLs.

In the example above, the entity could be checked against Freebase, using MQL, to determine some kind of category, such as actor, sports player, or singer. From here, this knowledge could be used to dynamically change the title tag pattern, aligning that entity with a more effective set of targeted keywords.
Linked Data Powered Internal Links
Leveraging linked data for page content and keyword targeting doesn’t have to be limited to page content only. It can be used to improve internal navigation and information architecture by helping to organize content into a logical ontology and by building internal linking structures based on the relationship between entities.

In the example above, Emma Watson can be connected to Paris as well as James Franco. This could be used to build content like “Famous celebrities from Paris / France” or to power features like related actors. When paired with an understanding of the most popular entity attributes, this can be used to build a powerful internal linking structure at scale.
Continuing to Develop
Search is radically changing right in front of us, continuously creating new opportunities to leverage SEO to drive visibility for businesses and website in organic search. Even this week, Google expanded conversational search to include voice search in apps, which allows users to say things like “Ok Google, search Hawaiian pizza on Eat24″ to open up Hawaiian pizza inside the Eat24 app, simply by adding a few lines of code to an apps AndroidManifest.xml file. As indexation expands, so will traditional technical SEO and content development, opening up a wide range of new tactics for getting exposure in organic search.