Related Search (or Categories) can be a powerful feature for SEO and UX (discovery). For SEO, Related Search can cross-link between two similar pages independent of their hierarchical relationship. Features like breadcrumbs interlink within a lineage, but Related Search can link horizontally outside of the lineage. Related Search can also connect pages without a defined taxonomy, such as indexable search pages (programmatic category pages created by a search stack).
This is helpful for a few reasons:
- “PageRank Sculpting”: Internal linking can push more link value around the site, increasing the inlink count and Internal PageRank strategically.
- Reduce Depth: Well-defined hierarchical structures can generate greater “click-depth” or Closeness Centrality. Related Search is a way to “skip ahead” in the crawl depth or create new horizontal paths.
- Create Crawl Discovery Path: Indexable search pages may have no natural discovery source on a website, requiring reliance on XML or HTML sitemaps for discovery. Related Search provides inlinks for discovery, so these page types aren’t orphaned.
Outside of SEO, Related Search has UX benefits. It can improve discovery, time on site, cart size, conversion, and RPV. It’s a supplemental feature that users can use to navigate the site.
In this post, I will build a basic related search system that recommends similar categories for each category on a real-world e-commerce website.
Examples of Related Search
The “indexable search page” + Related Search tactic is frequently used on many large sites. We’ll create the data required to power this type of feature.
Here are a few examples.
1) Etsy


2) Yelp
3) Getty Images

(I was the Product Manager for this feature years ago.)
Limitations with Paid Solutions
Some services provide solutions for this, but they have limited customization or tools to deal with relevancy short-comings. In-house solutions can offer more flexibility.
A few things I like to customize:
- Prioritization / Weighting: It’s helpful to sort/filter suggestions by business priorities in addition to relevancy. This could include pages with high striking-distance opportunities, pages that need more internal PageRank, pages that get a high CTR, or pages with high RPV.
- Excluding Already Linked URLs: If a site has robust linking features already, the Related Search links can be redundant. For example, the pages linked in the Breadcrumbs are likely to be highly similar, but linking to them is a redundant link on the page.
- Overcoming Relevancy Issues: Even sophisticated approaches can generate odd matches due to keyword overlap. Womens’ categories can recommend Dog categories, Kids’ can recommend Mens’ categories. We may want to account for these types of attributes, which can be site-specific.
- Complex “Windowing” Rules: Perhaps we want different logic for each link position in the suggestions. For example, perhaps the first two links should be a specific page type. Maybe we don’t want any more than N links from the same lineage.
- Boost/Exclude/Pin/Override: There may be a need for granular control and manual overrides. There may be pages to exclude.
An in-house solution can allow you to iterate on your recommendations over time to improve them.
Overview of the Recommendation Workflow
Here is the process we’re going to go through to create our recommendations.
- Crawl and parse text data from all Category/Search pages
- Use NLP to clean the text and simplify (lemmatization) the tokens
- Create a Bag of Words model for all pages
- Calculate the Cosine Similarity between all pages
- Find the top N most similar for each page
- Create a JSON file with source > suggestion pairs for all pages
Getting the Data
I will build recommendations for Ulta’s categories pages (not affiliated, not a client). Our first task is to extract text data from each page. We’ll use this text to compare pages.
I’m going to use their navigation XML Sitemap, crawl those URLs, and use XPath to extract some text from the page. I’ll exclude their /brand/ URLs for this demonstration.
Extracted Text:
- name (h1)
- breadcrumbs
- subcats
- product descriptions for page one
- facets/filters
You can use any crawler that supports custom extractions to do this, such as Screaming Frog. I’m using Python because it’s a well-defined, limited-scope task. I’ll extract what I need and won’t need to do as much data wrangling after.
I’m using requests to fetch the pages and lxml for my XPath extractions and for XML Sitemap parsing, but there are many ways to do this, such as Beautiful Soup or Scrapy.
This step is very site-dependent. I won’t go into much detail, as the choices I made are specific to Ulta. If you have any questions, though, let me know in the comments.
Here is the code (it’s a stand-alone script):
import requests
import lxml.html
from lxml import objectify
from random import randint
from time import sleep
import pandas as pd
# Set wait times to throttle requests
# Minimum wait + tandom wait
min_wait = 1 # Minimum seconds between
random_min = 0 # Min for random variance
random_max = 2 # Max for random variance
# Set request headers
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36',
}
#Parse URLs from XML Sitemap
xml = objectify.parse('data/navigation0.xml')
root = xml.getroot()
urls = root.getchildren()
url_list = [url['loc'].text for url in urls]
#Exclude /brand/ URLs
url_list = [url for url in url_list if "/brand/" not in url]
#Create DataFrame to Store Data
df = pd.DataFrame(url_list)
df.columns = ['url']
# Create New Columns for Extracted Data
df['name'] = ""
df['breadcrumbs'] = ""
df['subcat'] = ""
df['products'] = ""
df['refinement'] = ""
# Loop through list of URLs
i = 0
for url in df['url']:
# Request URL
response = requests.get(url, headers=headers)
# Create lxml HTML Object
doc = lxml.html.fromstring(response.content)
# Extract H1 (name)
h1_extract = doc.xpath("//*/h1/text()")
# Clean up extracts
h1_extract = [x.strip() for x in h1_extract]
# Convert list to string and store in DataFrame
df['name'][i] = ",".join(h1_extract)
# Extract Breadcrumbs
breadcrumb_extract = doc.xpath(
"//*/div[@class='brand-breadcrumb-ul']/ul/li/a/text()")
breadcrumb_extract = [x.strip() for x in breadcrumb_extract]
# Exclude 'Home' Breadcrumb
breadcrumb_extract = [x for x in breadcrumb_extract if "Home" not in x]
df['breadcrumbs'][i] = ",".join(breadcrumb_extract)
# Extract SubCats
subcat_extract = doc.xpath("//li/span/a/text()")
subcat_extract = [x.strip() for x in subcat_extract]
# Remove product count from string "Cat_Name (#)"
subcat_extract = [x.rpartition(" ")[0] for x in subcat_extract]
df['subcat'][i] = ",".join(subcat_extract)
# Extract Product Description
product_extract = doc.xpath("//*/p[@class='prod-desc']/a/text()")
product_extract = [x.strip() for x in product_extract]
df['products'][i] = ",".join(product_extract)
# Extract Refinements
refinement_extract = doc.xpath("//*/ul/fieldset/li/label/text()")
refinement_extract = [x.strip() for x in refinement_extract]
df['refinement'][i] = ",".join(refinement_extract)
i += 1
#Throttle time between requests
sleep(min_wait + randint(random_min, random_max))
# Save to CSV
df.to_csv('data/extracted.csv', index=False)This gives me a CSV of the extracted data.
Note:
There were some edge cases to the XPath on some pages, so I didn’t extract everything from every page. I didn’t worry about this for this blog post. If I was building this for real, I might add some more logic to handle those edge cases. Additionally, Ulta’s H1s aren’t always great, which I’ll talk about more later.
Cleaning the Text with NLP
The raw text I’ve extracted needs a bit of work before we proceed. I’ll be using spaCy for Natural Language Processing. This is because we’ll be comparing the words used in each document, and I want the text I put in to be clean and reduced.
Text Cleaning Steps
- Combine into a single text blurb: I’m going to concatenate all of the text fields I extracted into a single text blurb and deal with them all at once.
- String manipulation to clean up text: Some artifacts related to Ulta and how I scraped need cleanup. For example, I removed characters like “&,” which Ulta uses in their naming conventions and other issues like double spaces. My goal is to remove any oddities in the text before I pass it into spaCy. spaCy can do a lot of heavy lifting, but it’s good to clean things up a bit to avoid oddities.
- Lemmatize the words: Lemmatization is the process of reducing a word to its base version. I don’t want to miss matching words because two pages use different variants of the same word.
- Exclude stop words: I’m excluding stop words (common words like “the”). I don’t want to match documents on terms that aren’t relevant to that document’s subject.
- Exclude other word types I don’t want: There are other word types I wish to exclude, such as numbers or overly short words. There are also some words I extracted that I don’t want to be considered, such as “buy,” “sale,” and “purchase.” These are unique to the Ulta extraction and are common words within the corpus that I don’t want to be used for similarity matching. (I didn’t spend much time looking for these. I may have missed some, but I wanted to show a few examples.) These excluded words are unique to a corpus or a topic domain. For example, movie-related text might include words like “actor,” “director,” and “film” on many or all documents.
Here is the code (it’s a stand-alone script that processes the crawl export):
import pandas as pd
import spacy
#Load custom extraction into a DF
text_data = 'data/extracted.csv'
df = pd.read_csv(text_data)
#Combine Extracted Fields
df['all_text'] = df[['name', 'breadcrumbs', 'subcat', 'products','refinement']].astype(str).apply(lambda x: ' '.join(x), axis=1)
#Load NLP model
nlp = spacy.load('en_core_web_trf')
#Create new column
df['clean_text'] = ""
#List of custom stop/excluded words
excluded_words = ['buy', 'sale', 'save', 'gift', 'purchase', 'more', 'free']
#Looping through DataFrame and Process Text
i = 0
for text in df['all_text']:
#Remove odd characthers
text = text.replace(",", " ")
text = text.replace(".", " ")
text = text.replace("&", "")
text = text.replace("+", "")
text = text.replace(" ", " ")
#Crate spaCy document object
doc = nlp(text)
#Create a list of lowercase lemmatized words
#Exclude stop words, punctuation, custom excluded, numbers, and those with a len <2
clean_text = [word.lemma_.lower() for word in doc if word.is_stop ==
False and word.is_punct == False and word.lemma_.lower() not in excluded_words and word.like_num == False and len(word.lemma_) > 2]
#Convert list to string and store in DF
df['clean_text'][i] = " ".join(clean_text)
i += 1
#Save to CSV
df.to_csv('data/nlp.csv', index=False)I now have a CSV with all my extracted data and the cleaned-up text appended as a new column.
Creating a Bag of Words Model
A Bag of Words Model converts text into a list of unique words and their count. Word order and grammar are not maintained.
For multiple “documents” or strings, it can be represented in a matrix such as this:
| dog | bark | fetch | ball | |
| The dog barked at a dog | 2 | 1 | ||
| A barking dog | 1 | 1 | ||
| The dog fetched a ball | 1 | 1 | 1 |
The columns represent every unique word in the corpus, and each cell contains a count of how many times that word was used in the document.
We’re going to use CountVectorizer from scikit-learn to create this. CountVectorizer converts a collection of text documents to a matrix of token counts (i.e., the table above). It produces a sparse matrix. A sparse matrix is a matrix where most values are zero, and the zero values aren’t stored.
The output will be a table like the one above, but for all 270 categories on Ulta. It will have 4,875 columns, one for each unique word found across all of the pages.
I’ll share the code, then explain what it’s doing.
(The rest of the code in this post is in the same script. The imports below are used for all the remaining code examples.)
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from collections import defaultdict
import numpy as np
import json
# Import Processed Text
text_data = 'data/nlp.csv'
columns = ['url', 'name', 'clean_text']
df = pd.read_csv(text_data)[columns]
# Create list of text documents and list of URLs
text_list = df['clean_text'].tolist()
url_list = df['url'].tolist()
# Create the Document Term Matrix (BoW)
count_vectorizer = CountVectorizer(stop_words='english')
count_vectorizer = CountVectorizer()
sparse_matrix = count_vectorizer.fit_transform(text_list)
# Create DF for BoW
# Convert from sparse to dense matix (include zeros)
doc_term_matrix = sparse_matrix.todense()
bow_df = pd.DataFrame(
doc_term_matrix, columns=count_vectorizer.get_feature_names())
# For previewing
bow_df.index = url_listThere are three main steps in the code above.
1) Import Processed Text into a DataFrame
I import the CSV with the post-NLP text, so I have a DataFrame with URL, Name, and Clean Text.
(You don’t have to use Pandas for this, or several other things I use it for, but I find it easy to use and preview the data.)
2) Convert DataFrame Columns to Lists
I take the URL and Clean Text columns (Pandas Series) and convert them into lists. I’ll be using these for the BoW model and to set the index/column values in our DataFrames.
3) Create Bag of Words
We take our Clean Text list and pass it into CountVectorizer. This returns the sparse matrix object. I then use that sparse matrix to create a new DataFrame (converting it to a dense matrix that includes zero values). Lastly, I use the list with the URL values to set the DF index values.
This gives us a DataFrame that looks like this.
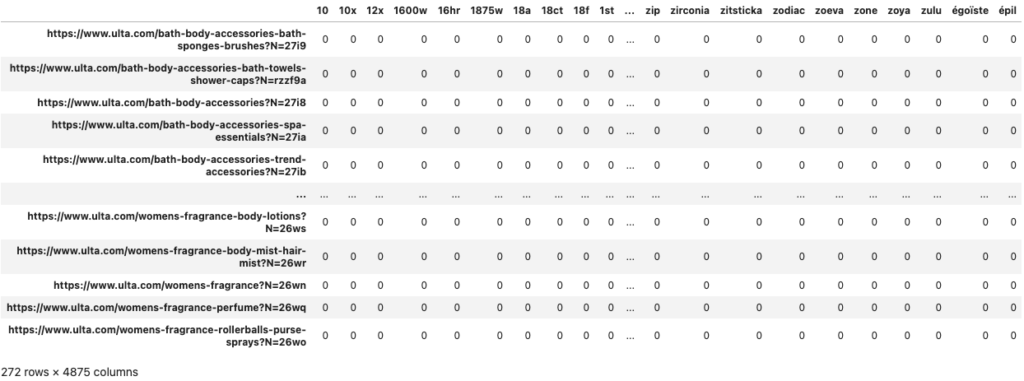
Every row is a URL, and the columns represent every unique word in the corpus. The value in each cell is how many times that word is used in the URL’s text.
We’ll pass this new DataFrame into the Cosine Similarity function.
Calculate Cosine Similarity
I won’t go into much detail on Cosine Similarity, but in this case, it’s a 0 to 1 score that measures similarity between our documents.
What is Cosine Similarity?
As intimidating as anything with the word “cosine” in the name can sound, the code for this is straightforward. You do not need to understand the math to use the function.
In simple terms, it “plots” our documents based on their words and then finds how close our documents are. Those that are closer are more similar. More specifically, our BoW matrix represents our documents as a vector in multi-dimensional space. Each row represents a document’s vector. Cosine Similarity looks at the angle between two vectors.
If you want more detail about the math, check out this video.
Creating a Cosine Similarity DataFrame
The function we’re going to use will take every document (URL) and compare it to every URL document. It will calculate a Cosine Similarity score for every pairing. We’ll take that output matrix and put it in a DataFrame
Here is the code (continuation of previous code example):
sim_df = pd.DataFrame(cosine_similarity(bow_df, dense_output=True))We put our BoW DataFrame into the cosine similarity function and saved it to a new DataFrame. I used my URL lists from before to set the index and column names.
We get a DataFrame that looks like this.
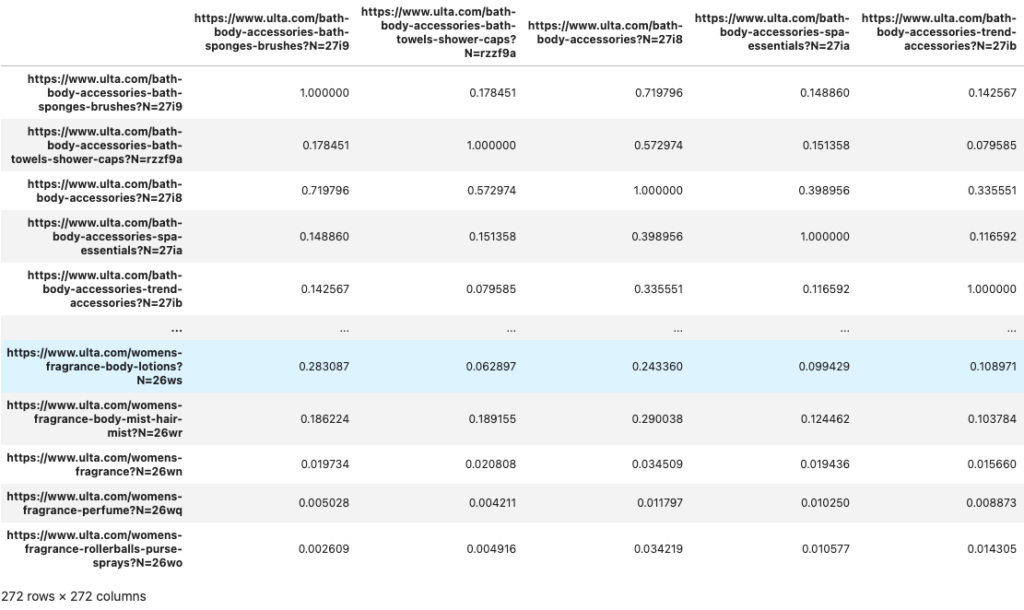
We have 272 URLs in the corpus. We have 272 rows and 272 columns. The values in the cells represent the similarity score for the row-column pairing.
If you look at the cells diagonally, the scores are all one. That’s because the URL is compared to itself. We don’t want to recommend the URL you’re already on, though. When the row and column are the same URLs, we’ll set the score to zero. Let’s do this and replace the current DataFrame.
Here is the code:
# Reduce self-scores to zero
similarity_list = []
for j, k in enumerate(sim_df.values):
for n in range(len(k)):
# If row = column, change 1 to zero
if j == n:
similarity_list.append([j, n, 0])
else:
similarity_list.append([j, n, k[n]])
clean_dic = defaultdict(list)
for i in range(len(similarity_list)):
clean_dic[similarity_list[i][0]].append(similarity_list[i][2])
sim_df = pd.DataFrame(clean_dic)
# Add URLs as index and column names
sim_df.index = url_list
sim_df.columns = url_listI’m iterating through all the cells in our similarity score DF and building a list that contains the cell’s position information and its value. While doing this, I’m checking to see if the row index is the same as the column name. If these match, it means it’s the score created when comparing a URL to itself. Instead of storing its current value of 1, we replace it with a zero. If they don’t match, we keep the current value.
I then use our list of values to construct a new dictionary. We’ll use this dictionary to create a new DataFrame to replace our last one.
Here is our new Cosine Similarity DF (the diagonal starting from the top-left most cell are now all zero):
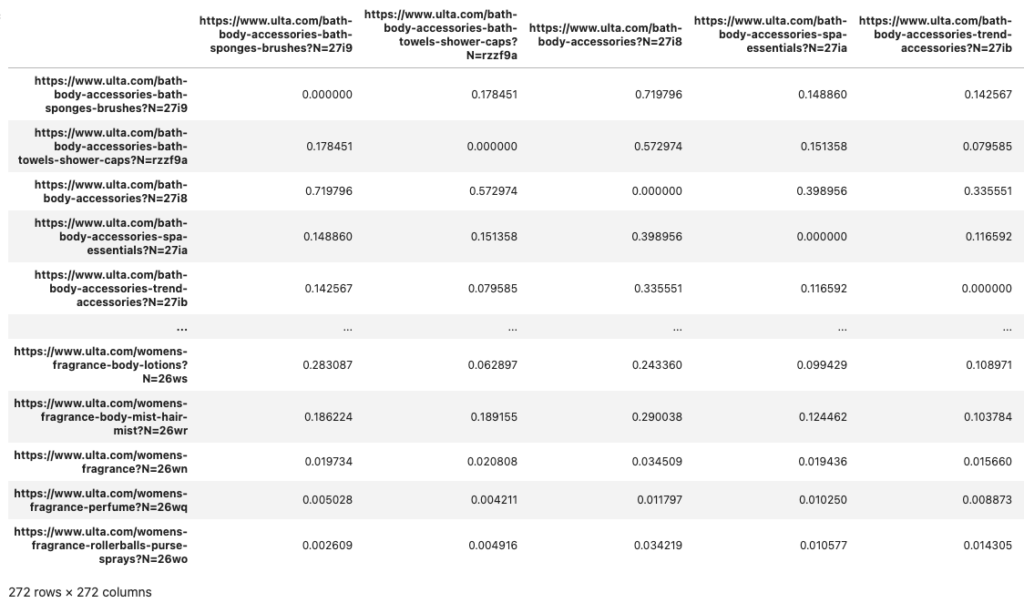
We now have the data we need. Next, we need to evaluate and extract the top related URLs.
Finding the Most Similar Pages
We need to find which other URLs for each URL have the highest similarity score. In simple terms, we need to sort each column in our Cosine Similarity DataFame by descending order and extract the top N URLs by their score.
There are two caveats to this extraction.
1) There may be <N URLs with an acceptable similarity score.
We may want to truncate the list of suggestions if we’re getting too irrelevant. We can solve this with a minimum similarity score (i.e., don’t return URLs with Cosine Similarity < X). This means there may be fewer than N relevant URLs to suggest (I’ll talk about this at the end of the post).
2) Pages with very high similarity scores may be linked already.
These pages are likely in the same hierarchy/lineage and already linked via breadcrumbs and subcats. It’s not a big deal, but perhaps a wasted opportunity to add an incremental outlink.
We could solve this by filtering out the URLs we know the page links to already, or we could get close enough by setting a maximum score. For example, if we exclude suggestions with a cosine similarity >X, we may reduce the likelihood of suggesting a close relative that is already linked. This isn’t a perfect solution and may create some collateral exclusions. Solving this more robustly is out of scope for this post.
I don’t have a good recommendation for Max/Min values. It depends on your data and goals. I suggest a bit of trial and error until you’re happy with the results.
Sorting Through Our DataFame
Here is the code, and then I’ll explain it.
# Create dictionary with most similar URLs suggestions for each URL
related_dic = {}
# Iterate through columns
for i in sim_df:
# Convert column to dictionary
similarity_dic = sim_df[i].to_dict()
# Sort dictionary based on values
similarity_dic = {k: v for k, v in sorted(
similarity_dic.items(), key=lambda item: item[1], reverse=True)}
# Create list of the URLs from dictionary but limit based on a max and minimum relevancy score
similarity_list = [k for k, v in similarity_dic.items() if 0.4 > v > 0]
# Create a dictionary to store URL and name
suggestions_dic = {}
# Loop through list of similar URLs we extracted from dictionary
# Limiting to the first 6 URLs - you can change this to get more or less
for url in similarity_list[:6]:
# Looking ul the URL in the NLP data DF to get its name (h1)
name = df.loc[df['url'] == url]['name'].values[0]
suggestions_dic[url] = name
# Add dictionary to our dictionary for all URLs
related_dic[i] = suggestions_dicI iterate through each column in our DataFrame. I convert each column (Series) into a dictionary (URL-score pairs). I then sort that dictionary based on the similarity values. I then extract the top N keys (URLs) from that dictionary but limit them based on max and minimum score values. In other words, what are the top 6 URLs with values less than our max but greater than our minimum?
You can customize the max (0.4), min(0), and N count (6) values I used based on your needs and the quality of your results.
Now that I have a list of the top N suggested URLs within our max/min range, I want to associate them with the name I extracted for each URL (the H1). I can use this name as the anchor text for the link, so I want to include it in the final JSON. I create a new dictionary to hold my suggestions for each URL. I set the key to the URL and the value as the page’s name.
Lastly, I created a dictionary that holds all my suggestions for all 272 URLs. Each key is the lookup URL, and the value is a dictionary with the name-URL pairs for the suggestions.
What this dictionary looks like will make more sense when you see the JSON dump below.
Note:
The extraction process didn’t always capture a good “name” for a category, but that’s an issue with what Ulta includes in their H1s. For example, the H1 for “travel size hair products” is just “Travel Size” (same for the title). If Ulta optimized their H1s or Titles, we could use them as-is; otherwise, I’d suggest constructing them based on the breadcrumb using a pattern such as [Breadcrumb 1] [H1] or manually rewriting them. Since this is for demo purposes, I didn’t do these types of optimizations.
Creating a JSON Dump
Now that we have a dictionary, we can easily dump it to JSON. This JSON can be used on the backend or frontend to render the suggestions. You can look up any category URL and get back up to 6 suggestions with their name (anchor) and URL. It’s also not that much more work to create a REST API that lets you look up suggestions by URL.
The code for this is simple.
# Serializing JSON
json_output = json.dumps(related_dic, indent=4)The resulting JSON looks like this.
"https://www.ulta.com/gel-nail-polish?N=278j": {
"https://www.ulta.com/nail-polish-stickers?N=y5vfsk": "Nail Polish Stickers",
"https://www.ulta.com/nails-top-base-coats?N=27iq": "Top & Base Coats",
"https://www.ulta.com/press-on-nails?N=lrb2l2": "Press On Nails",
"https://www.ulta.com/nail-art-design?N=27br": "Nail Art & Design",
"https://www.ulta.com/nails-manicure-pedicure-tools?N=27ir": "Manicure & Pedicure Tools",
"https://www.ulta.com/bath-body-hand-foot-care-manicure-pedicure-tools?N=27if": "Manicure & Pedicure Tools"
},
"https://www.ulta.com/men-hair-conditioner?N=26zx": {
"https://www.ulta.com/hair-shampoo-conditioner-shampoo?N=27ii": "Shampoo",
"https://www.ulta.com/men-travel-size?N=27cp": "Travel Size",
"https://www.ulta.com/men-body-care?N=wpkeo8": "Body Care",
"https://www.ulta.com/hair-shampoo-conditioner-dry-shampoo?N=27ij": "Dry Shampoo",
"https://www.ulta.com/hair-travel-size?N=27ci": "Travel Size",
"https://www.ulta.com/bath-body-bath-shower-shower-gel-body-wash?N=26uz": "Shower Gel & Body Wash"
}You can use dump instead of dumps to save it as a file. Here is the code for that.
# Save to JSON file
with open("related.json", "w") as outfile:
json.dump(related_dic, outfile, indent=4)Here is the JSON file I created.
One risk to keep in mind is that your suggestions can become stale and stock availability changes. You’ll want to refresh this periodically based on your inventory changes. You may also want to validate that URLs have a 200 status code and are indexable/canonical. Discovering URLs via XML sitemaps can be helpful if you already have these validations build into your sitemap creation.
Ways to Improve the Suggestions
This is a decent enough initial version, but there is room for improvement and iteration. I shared some ideas in the “Issues with Existing Paid Solutions” section, but have a few other suggestions below.
Additionally, there are entirely different methods for determining or retrieving similar documents. I’ve built a similar concept using a text search solution like ElasticSearch by constructing queries against an index of category page content.
Independent of your initial “similarity” / “relevancy” score, here are a few ways to improve suggestions.
1) Integrate Business Performance Metrics
Cosine Similarity can be one of many inputs for sorting. You should add performance metrics (visits, GSC clicks, revenue, RPV). You can pull the top N suggestions by relevancy and then sort/filter them by those business metrics. Alternatively, create a calculated score based on multiple weighted inputs.
2) Compare Opportunity with Internal Page Rank
Create a 2×2 matrix that compares visits/opportunity(search volume) with Internal PageRank. Find the URLs in the quadrant with high opportunity and low PageRank. Use Related Search to boost their discoverability.
3) Audit Suggestions and Tune Results
Audit what gets linked to by what. Audit what receives the most inlinks from this feature. Make adjustments to your NLP or scoring to optimize.
You may find keywords that create odd relevancy matching. You can exclude them.
You may find a longtail distribution for inlinks per URL. A few URLs may get an excessive number of links. Explore why and add in logic to try and normalize the distribution. This can happen when you use business metrics or PageRank. There is a risk of over suggesting your best pages and reducing diversity. Try to normalize the distribution of inlinks provided by the feature.
You may find certain page types are over-or underrepresented. Using “windowing” to either limit the number of slots a page type gets or guarantee slots.
4) Fill Gaps
In my example, I returned up to 6 suggestions, but not all URLs may have 6 relevant URLs. You could conditionally loosen the max/min range in these situations or find alternative logic to fill these gaps. This way, fewer link slots are wasted (careful though; you don’t want to harm relevancy for users).
You might want to track link slot utilization, which is [total number of suggestions] / ([max link slots] * [number of URLs the feature appears on]). This number can indicate some relevancy issues (or may reflect sparse data for matching or a limited assortment of suggestion candidates).
5) Integrate Existing Outlinks Data
During the crawl, you could extract internal outlinks for each URL. You can filter suggestions based on existing outlinks, so a redundant link is not suggested. With this, you could increase the maximum bound on your relevancy, which might be excluding highly relevant pages outside the lineage.
6) Build Relationships on Other Attributes
There are other ways to match URLs or filter suggestions depending on your data. For example, entities could be used for filtering. If you’re dealing with cities, you could filter by the same city or same state. If you’re working with movies, you could filter by the same director, actor, or genre.
This could be combined with windowing as well. Three slots for all pages. Two slot for entity type A. One slot for entity type B.
7) Track Clicks
You can also set up web analytics to track clicks. This can give feedback on CTR and downstream business metrics. This can be used to pin results by position or weight certain result types that perform well.
You may find that there is a CTR curve by position, so be careful here. The first few links will tend to have better CTR, so look for better than average by position or try randomizing order for testing purposes.
The order may have less impact on SEO but may help squeeze out better on-site performance metrics.
This data can also be used to test/validate the quality of results, helping you exclude suggestions that users don’t click.
8) Anchor Optimization
Some e-commerce sites are locked into short, less descriptive “name” fields because the same field is used for navigation features (facets, subcats, breadcrumbs). While this is theoretically fixable by giving each page two name fields, it may be challenging to get that feature released.
If this is the case, many internal inlinks to a page with this problem may have suboptimal anchor text. For example, Ulta may rarely link to their “Travel Size Hair Products” category with the word “hair.” Related Search can help supplement this. Simply tweak the “name” you’re using for a URL to optimize its internal anchor text (“Travel Size Hair Products”).
9) Add Images
Etsy is an excellent example of using images with Related Search/Categories. You could extract the top product image URL from each page and include it in your JSON dump. This can provide a more visual presentation.
If you’re finding that interactions with this feature is improving business metrics, images may improve CTR. Images can also make the feature more appealing for “above-the-fold” use or mobile.
10) Use It Strategically
Once the feature is in place, there are a few strategic ways to leverage the feature by pushing inlinks to a page on demand. There are various degrees of “aggressiveness” here, but a simple example is a seasonality variance.
A seasonality input could be used to sort, boost, or manually insert recommendations. This can put more weight behind a subset of URLs during a critical period of inflated demand. Maybe it’s enough to move a position or two on a few keywords during a crucial time.
Again, keep UX in mind when boosting suggestions. You don’t want to suggest irrelevant pages accidentally.