A week ago, Matt Cutts posted a video discussing what SEOs could expect in the coming months. One of the mentioned updates was around host or domain clustering / crowding. I think some type of domain crowding update went out, starting last night. Hat tip to Jason Mun for noticing.
Specifically what Matt Cutts said about domain clustering was [emphasis mine]:
We’ve also heard a lot of feedback from some people about that if I go down three pages deep I’ll see a cluster of several results all from one domain. We’ve actually made things better that you’re less likely to see that on the first page and more likely to see that on the following pages. And we’re looking at a change which might deploy which would basically say that once you’ve seen a cluster of results from one site then you’d be less likely to see more results from that site as you go deeper into the next pages of Google search results.
And that has been good feedback that people have been sending us. We continue to refine host clustering and host crowding and all those sorts of the things. But we’ll continue to listen to feedback and see what we can do even better.
Thanks to Ross for transcribing the video.
There appears to be changes in the number of results from a single root domain shown for a particular query. It doesn’t seem to be showing up consistently in all countries though.
Site Search Edge Case
You’ll most easily notice this when you perform a site: search against a domain. It’ll limit the results to 3 pages and show between 28 and 30 results before it gives you the omitted results statement. The consistent part is 3 pages, but the exact numbers vary in the high 20’s.
For example, here is a site:amazon.com search.
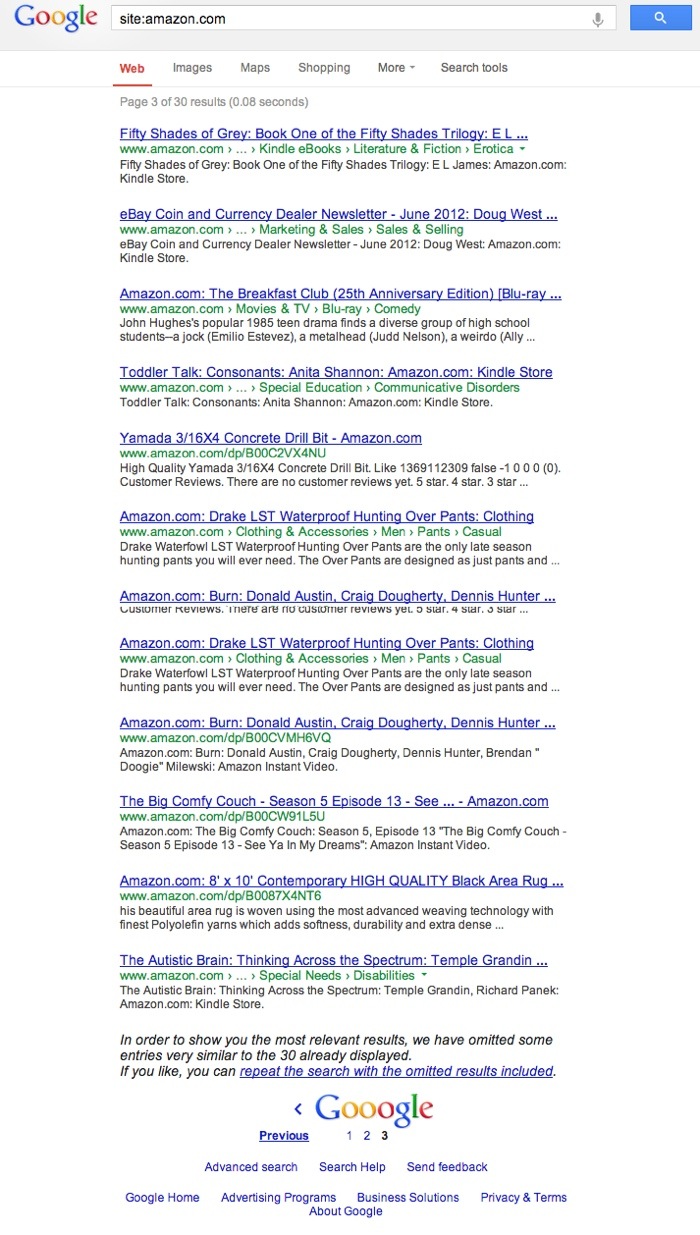
This “omitted results” prompt usually shows when you dig deep enough that the indexed URLs start to become duplicate, near duplicate, or relatively low value. However, now it appears to be truncating at 3 pagination pages, regardless of the site’s authority or information architecture. It doesn’t appear on sites with < 30 pages, but seems to show on anything from 30+ to something the size of Amazon.com.
This is a new change that appears to be tied to anti-clustering of domains. It also applies to domains with heavy subdomain usage, like tumblr.com.
The filtering appears to be controlled by the omit results filter parameter “filter=” with a setting of 1 or 0.
For example, the URL to repeat the site: search without the omitted results is:
https://www.google.com/search?q=site:amazon.com&rlz=1C5CHFA_enUS504US504&biw=1248&bih=731&filter=0
Domain Filtering in SERPS
The site: search appears to be an edge case of what’s occurring. I tested heavy brand queries that would have few other domains to show outside of the primary brand’s domain.
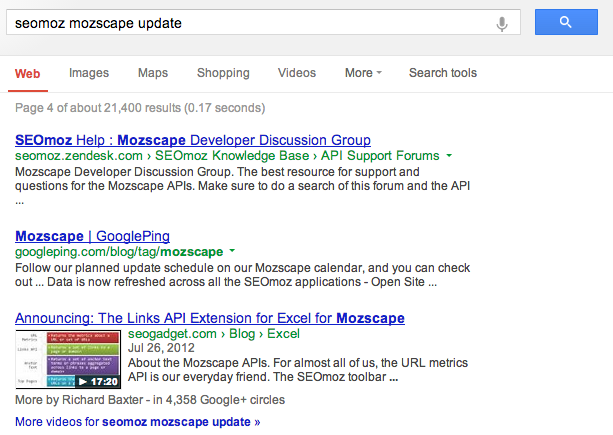
A search for “seomoz mozscape update” shows 29 results from SEOmoz.org and stops after page 3. This pattern persists across a number of domains.
Example searches:
- imdb actors inurl:imdb.com
- pinterest quote inurl:pinterest
- iacquire mike king inurl:iacquire.com
- seomoz rand fishkin inurl:seomoz.org
- bigfishgames walkthrough inurl:bigfishgames.com
However, the filter= parameter disables the anti-crowding effect, and not just when prompted at the end of search pagination.
It disables it broadly, as the filter is active on all searches by default.
For example:
https://www.google.com/search?q=seomoz+mozscape+update
will limit results from seomoz.org at page 3, showing other domains beyond that.
Here is the top of page 4 with domain filtering active (no added parameter).
However, using the filter parameter will show seomoz.org past page 3.
https://www.google.com/search?q=seomoz+mozscape+update&filter=0
(You’ll notice the addition of &filter=0 at the end, disabling the omit feature, which appears to control the anti-clustering)
Here is the top of page 4 with domain filtering disabled.
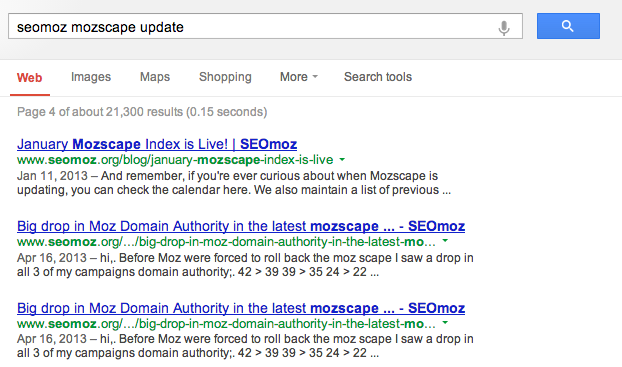
Actually, it shows all SEOmoz.org results until page 6, and even then, most of page 6 is the SEOmoz.org domain. Even on page 20, I’m seeing mostly SEOmoz.org results.
This appears to be applied more broadly as well. However, there appears to be two different parts to the anti-clustering. The first applies to page one results. Even with the filter is disabled, there is still a decent degree of diversity, depending on how broad the term is and if there are other relevant domains for the term. However, once you click past page one, the diversity appears to fall off. This is where the second, newer, filter is playing a role.
An example of this is “seomoz whiteboard friday” where SEOmoz.org holds 8 of the 10 results on page one and none of page two with the filter active. Once the filter has be deactivated by setting the parameter to zero, SEOmoz.org holds the first 19 positions.
Ways Google May Handle Domain Clustering
My guess is that Google is solving domain clustering by:
- Promoting a diversity of domains, especially on page one and two.
- Leveraging site links to minimize real estate of one domain. The filter parameter appears to affect sitelinks as well.
- Adding this new filter that more explicitly minimizes content from domains already seen.
- Creating a type of hard limit at pagination 3 that will not show any more from a domain past that page.
This new hard limit makes sense for usability. If a user has already seen the top 10 to 30 most relevant URLs from a particular domain, there is a good chance that domain doesn’t have their answer, especially if they take the step to click to page 4 and beyond. The one edge case where the logic seems flawed is the site: search. In that case, the user is explicitly searching for content from a specific domain.
Great investigative work mate. Would be good to get a comment/confirmation from Google.
I’ve started another thread on Google+ and got John Mueller’s attention.
Great post Justin – thanks for this research – very helpful – for those of us who do site searches in their browsers all the time and want to remove the omitted results 3 page limitation for site audits, here’s the search engine shortcut code for chrome, along with non-personalized search –
Nice work here Justin. I see this filter impacting host crowding on the first page of results.
It would be nice if they exempted the site: queries, though I suspect we SEOs are one of a handful of industries that uses that operator on a regular basis. It’ll be interesting to see if they test different weights of host clustering via this filter over time.
Nice research, Justin.
Great post Justin! and very nice responsive website #RWD
Awesome post Justin.
I was wondering if Google is doing this filters in preparation for a new Google update…
Today, I have also noticed that my site result is also showing only 30 results, on that I am confuse but when I read your article then I realized that it is a bug..