To understand more about how JavaScript works, read this post on the Core Principles of SEO for JavaScript.
Auditing a page that uses JavaScript to render content is a more manual process than traditional auditing due to a lack of JavaScript support in SEO tools. In this post, I’m going to walk-through how to perform a simple audit of a page that depends on JavaScript.
Steps for Auditing JavaScript
- Visually Audit the Page
- Audit HTML Source for Missing Content
- Audit JS-Rendered HTML for Missing Content
- Compare the HTML Source and JS-Rendered Source for Contradictions
- Identify Content Dependent on User Events
For this audit, I’ll be using Chrome, the built in developer tools, and the web developer extension.
As an example, I’ll be looking at this product page:
http://www.kipling-usa.com/angie-printed-handbag/HB6961.html
On this page, there are 3 major pieces of content that depend on JavaScript:
- Reviews
- Related Products
- Product Image Carousel
1. Visually Audit the Page
Get a sense for the user’s experience when visiting a page. I’m typically making the following list:
- Outline of the content visible on the page
- Content that requires an interaction
- Content that’s hidden by default
- Content that uses 3rd party tools (ratings & reviews)
- Content that uses recommendation systems (related products)
This list gives me an idea what I should expect to find in the source code of the page. The goal is to ensure that all content visible to users is indexable.
2. Audit the HTML
This is a traditional audit. However, because content may rely on JavaScript rendering, some content may not be captured in traditional SEO auditing tools. This includes Google Structured Data Testing Tool.
First, I disable JavaScript, CSS, and Cookies in the web developer extension. The goal is to identify what is missing from the page.
On our example page, related products and ratings and reviews disappear. The functionality of swapping product images does not work.
The second step is to manually review the HTML source, in particular the title, meta tags, and crawl control (noindex, canonical, etc).
Content that is missing during this step is reliant upon JavaScript rendering to be indexed. That content must be accessible by the load event (or by a 5 second timeout), which is about the time Google takes a snapshot of the page to be indexed. Additionally, this means this content is not indexable by bots with lower levels of JavaScript support (including Bing and Facebook).
To minimize impact on 2nd tier bots, I typically recommend that title, meta, social tags, and crawl control always appear in the HTML source of a page.
3. Audit the Rendered HTML
Enable JS and CSS, then refresh the page. Do not click anything. Right click anything on the page and select Inspect Element.
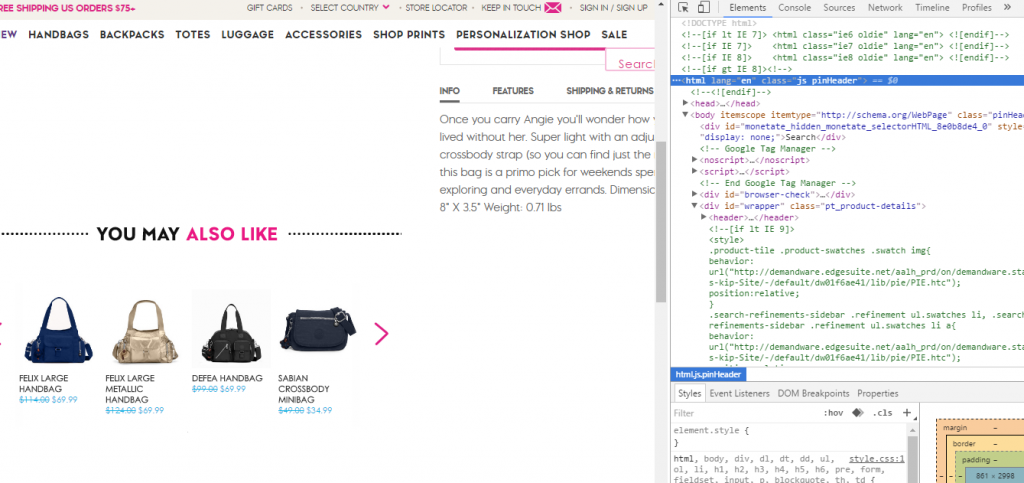
In the right pane that appears, scroll up and click the opening HTML tag. Right click it and select Copy -> Copy outerHTML.
This copied HTML is equivalent to what Google captures in the JavaScript crawl. You can also explore this code within Inspect Element / Elements pane.
This HTML can be copied and pasted into other tools, like the Google Structured Data Testing Tool. You can also save it out to an HTML file.
As a general rule, if the content appears in this copy and paste, it is indexable.
In our example, this captures reviews and related products. These two pieces of content are indexable via Google’s JavaScript crawling. You can test this by searching for a unique phrase contained in a review. However, this does not capture the large product images in the carousel at the top. They are dependent upon user events.
4. Compare Versions for Contradictions
At this point, there are two “versions” of the page: the HTML Source and the JS-Rendered HTML. These can contain different and sometimes contradictory content.
In general, the JS version gets priority, but there are some complexities that can be introduced with contradictions and missing tags. Avoid contradicting signals between these two pages.
There is less risk when we’re discussing small differences in textual content, but be cautious when looking at robots controls like noindex, canonical, and rel=next/prev. If there is a title rewrite, they typically go with the JS-Rendered version.
In some cases, you won’t know which Google will pick until you put the page in the wild. If something goes wrong, this comparison helps identify issues.
5. Identify Content Dependent on User Events
If you leave Inspect Element open and click on product image thumbnails, you can see the code updating in the browser in real time. This demonstrates how user events can change content on the page after the load.
These event-driven changes should be considered “non-canonical” and are not indexable.
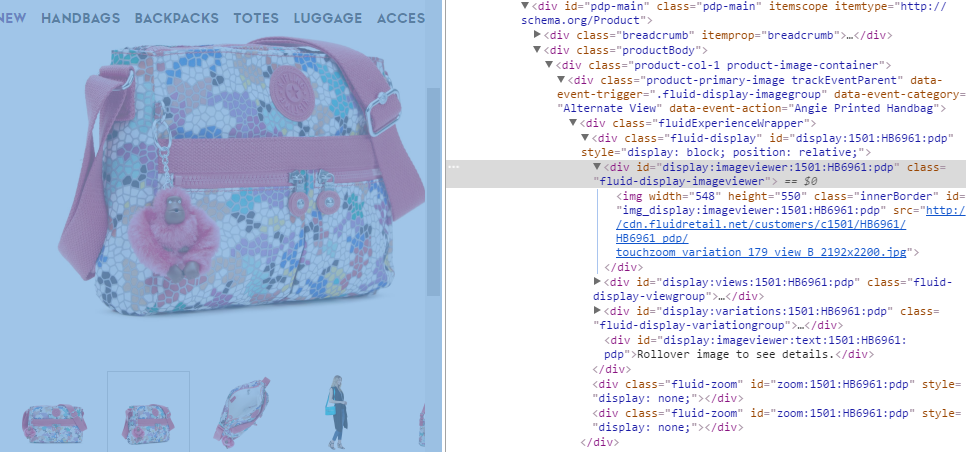
For the product images on the page, the only image embedded as a large image is the first image, the others are embedded as thumbnails. When a user clicks, the URL for the large image is changed in the src= attribute, referencing the larger image of the 2nd, 3rd, or 4th image.
This is a limitation of JavaScript crawling. The larger, non-thumbnail image of these variations do not get indexed in image search. This can be seen below where only the thumbnails get indexed in Google image search.
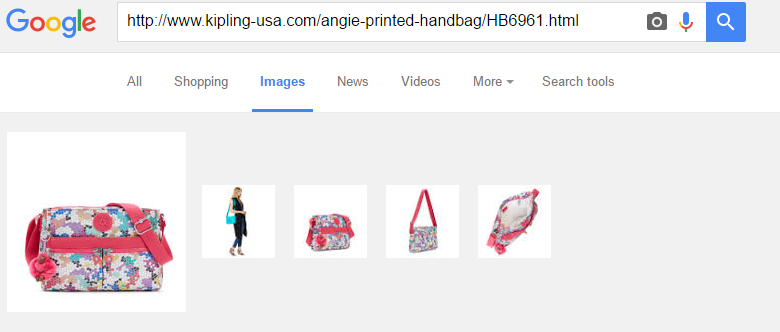
For these other images to be indexed, they would need to be referenced in img src in the HTML within the initial rendering of the page. While this is an interesting example, we don’t typically stress it for clients where image search isn’t a priority.
Common JavaScript SEO Issues
These steps will identify and manage common problems with JavaScript indexing, but there are some additional situations you’ll want to consider.
Indexable URLs
For a page to get indexed and rank, it needs a distinct, indexable URL. Several sites use single page apps and JavaScript-powered facets that do not create URLs for different “views”. If a distinct URL is not created and supported by the sever, this “view” is not indexable. If the URL for that page/view is not linked it, it may not be discovered. This is not a JS SEO problem, it’s a traditional technical SEO problem that commonly appears on JS-driven content.
Errors in pushState
Sometimes pushState errors can print out the wrong URL for a page, but the server will support both versions. This can create duplicate content issues, especially if the URL rules are used consistently in internal links. This is not a JS SEO problem, it’s a traditional technical SEO problem that commonly appears on JS-driven content.
Delays in Content Loading
If content appears in the Inspect Element, but does not appear to be indexed, it may be due to timing. It may come in after Google takes the snapshot of the page (load event or after 5 seconds). You can see the snapshot within the Fetch and Render tool.
Data Attributes
It’s a common practice in JS-driven pages to put resources, like images, in data attributes instead of traditionally supported attributes like img src. Content that does not follow traditional best practices for discoverability may not be indexed. You can always test, but if you want minimize risk, use more traditionally supported approaches.
These JS blogs are great! I’ll keep these in my back pocket!
Great tips Justin, I’ve learned so much from this post! Thanks a ton!