The shift to JavaScript crawling is one of the more significant changes in technical SEO in the last few years, but the conversation around it historically has been limited. When it is explored in-depth, it’s typically platform-specific or jargon-heavy. Many SEOs have a lot of confusion when managing requests from developers about JavaScript. However, the days of categorically recommending server-side support for content have passed. The current state of JavaScript is more nuanced.
These nuances can be hard to follow for anyone who is less familiar with with how JavaScript works. My hope is to provide a basic framework for anyone working in online marketing or product management, regardless of your current experience with JavaScript. However, I will follow up with additional posts where I do explore more theory, nuances, and tactics.
JavaScript can significantly improve user experience, so our goal in SEO is not to deter developers from using it, but to minimize negative business impacts as a result of search engine behavior.
Disclaimer: This post is just opinion, or, in other words, it contains a series of theories and hypotheses based on observations, tests, and trial and error. JavaScript crawling is complex and evolving, with each search engine at different stages of support. Additionally, search engines always reserve the right to behave differently in various circumstances. This post is meant to provide general advice around JavaScript optimization and may disagree with specific observations you’ve seen.
Can Search Engines Crawl JavaScript Rendered Content?
The short answer of “yes” is dangerous.
This simplified answer creates a lot of risks when product teams and developers move to a JavaScript-driven design without first exploring the nuances.
More accurately, Google can crawl JavaScript broadly, but there are caveats and limitations. Its JavaScript crawling isn’t as battle-tested as its HTML crawl. If you rely on Googlebot’s JavaScript crawl, you will eventually run into something that doesn’t work as intended. This is a risk that must be accepted when venturing into full JavaScript-driven pages.
Additionally, there are many more bots than just Google. These include Bing, social bots (Facebook, Twitter, LinkedIn), international search engines, and tools (monitoring, auditing, sitemap builders, link tools, etc). Most of these bots do not crawl JavaScript. The ones that do are behind Google in ability.
There has been a lot published and discussed about JavaScript to date. Interpreting what these posts mean can be challenging.
1) Thinking about Tests
It’s common to face an email from a developer that links to a blog post with a series of tests that attempt to clarify how Google deals with JavaScript. While these types of tests are excellent, giving SEOs confidence and blazing the trail to a better understanding Google’s ability, a simplistic interpretation of their results is dangerous.
Accepting these results as categorical confirmation of Google’s capabilities can be detrimental to revenue. Google can index content rendered by JavaScript effectively, but sometimes it doesn’t. These tests do not address why that may happen.
This isn’t because the tests are wrong. It’s because your implementation isn’t setup like these basic tests were. Take the time to test your implementation on a subset of pages to confirm that the content can be properly crawled and indexed before rolling out and risking revenue.
2) Google’s Own Statements
It’s also common to face the blog post from Google that states it can crawl JavaScript. They’re not being dishonest (they’re really quite good at it), but they don’t give enough specifics and put a lot of disclaimers between the lines.
In short, Google said they’re “generally able to render and understand” and “we recommend following the principles of progressive enhancement”.
Inverted, this means Google cannot render and understand all content that is dependent on JavaScript. They also have not changed their stance on progressive enhancement, which is really an HTML-first mentality.
3) Other Bots & Tools
A significant problem with relying on JavaScript is that other bots are often forgotten. While Google has made significant progress in its crawling abilities, Bing, Facebook, Twitter, LinkedIn, and international crawlers do not match Google’s capabilities.
It is valuable for many businesses to optimize for the lowest common denominator in crawl and indexation. These crawlers can influence millions in revenue. Is the business benefit of moving to a JavaScript-heavy approach worth the traffic trade-off of causing crawl problems with these other crawlers?
Luckily, there are some ways to split the difference and minimize the risk (maintain uniquely indexable URLs with title, meta content, and crawl control still served server-side… think of it as optimizing a Flash site).
“Other” bots also include your internal tools and monitoring systems. Check anything you use to “crawl” your site. For example, if you crawl your site to build XML Sitemaps, you could break its functionality by moving to JavaScript. Breaking these tools can create additional operational costs to a business by making a lot of automatic tasks manual.
This also includes the bots used by backlink tools. Links in JavaScript may not appear in your backlink profile, as reported by a 3rd party tool, but that does not mean Google doesn’t see them. However, it doesn’t mean it sees them either. You have to manually confirm that link is rendered in a way that Google indexes, at least until SEO tools catch up.
As a result, Briggsby still highly recommends a more traditional, HTML-first approach despite advancements in JavaScript crawling. Using more traditional approaches protects revenue by not relying on the abilities, tests, and success of product development at other companies.
4) Dealing with Frameworks
Another common method of addressing JavaScript SEO is to talk about frameworks. These discussions typically revolve around which ones are best for SEO and how to implement optimizations on each of them.
This is comparable to evaluating web server platforms, such as Apache vs. IIS vs. nginx, or CMS platforms, such as WordPress vs. Drupal vs. Adobe CQ. While some of these platforms are easier to work with, or come with already optimized features, they can all be made generally SEO-friendly. It’s less important what SEO plugin is used than it is what is in your HTML title tag. This is because Google is looking at the product, the code and the metrics, produced by these platforms.
The same is true for JavaScript indexing. Google is, generally, looking at the rendered content by the load event (or within a potential 5 second timeout.).
5) Understanding Crawl Efficiency & Resources Restraints
Parsing content that requires a modern headless browser that has to execute and render using JavaScript is more resource-intensive than fetching the HTML of a page and parsing it. This has real costs in terms of time, CPU, and electricity. Expect JavaScript crawling to be slower and more discriminating (dependent on authority). Conversely, expect search engines to use more traditional crawling to support just-in-time, core, and large-scale functionality.
If you’re looking for fast indexation, deep crawling, or struggle with other efficiency issues (duplicate content or parameters), JavaScript could have an effect. It could mean slower indexing.
Fundamentals of an HTML Crawl
Understanding JavaScript crawling requires a fundamental understanding of how traditional crawling works.
In short, the process of a crawl looks like this:
- Bot makes a GET request for a page (they ask the server for the file)
- Bot downloads the raw HTML file (same as your view source)
- Search engine parses the HTML, extracting content and meta data (location, tag, attributes, etc.) associated with that content
- Content is stored (indexed), evaluated, and ranked in a variety of ways
The “problem” with JavaScript is that the content that appears to users, what you see on your screen, is not findable via this method. In practical terms, when you view source, you do not see what appears to the user. Therein lies the problem with JavaScript.
JavaScript crawling is just the process of getting the code the user is seeing instead of what they download with the raw HTML. Search engines do this by using a browser to crawl instead of relying only on a download of the HTML document.
Before jumping into this, it’s helpful to understand what JavaScript is doing.
Fundamentals of Writing to Page with JavaScript
JavaScript can be complicated, but the parts you need to understand for SEO are simple.
This is, very simply and generally, what is happening when a browser requests a page that depends on JavaScript-rendered content. The Googlebot JavaScript crawler replicates this.
- Initial Request – The browser (and search bot) makes a GET request for the HTML and associated assets.
- Rendering the DOM – The browser (search bot) starts to render the DOM. DOM stands for Document Object Model. Don’t let this intimidate you. Ignore all those complex looking family tree graphs you see in presentations. This is basically the name for how the browser (search bot) understands how the content on the page is formed and describes the relationship. If you’re not comfortable with JavaScript, think of this as the browser (search bot) figuring it all out, creating an org chat, and building the page. This DOM can be interpreted (turned into visuals) by the browser (search bot).
- DOM Loaded – While working on a page, the browser (search bot) triggers events, one being DOMContentLoaded. This event means the initial HTML document has been loaded and parsed. It is in a ready state. In simple terms, it’s the browser saying it dealt with everything it downloaded and it’s ready for JavaScript to start doing work against the page.
- JavaScript Makes Changes – Following this, JavaScript can make changes to the page. In very simple terms, think of this is adding, deleting, or modifying content in the HTML source. It’s like opening a page in Notepad and changing the title. JavaScript can do a bunch of things, effectively recoding the page for a desired effect. That desired effect is represented in the browser and may not match what was in the original source code. This is the content you can see if you use Inspect Element in your browser.
- Load Event – The load event is fired by the browser when the resource and its dependent resources have finished loading. This is an important event, because it says, generally, that the page is “done.”
- Post-Load Events & User Events – The page can continue to change by content pushed to it or through user-driven events such as onClick. These are permutations on the page after it has completed.
Headless Browsers
The phrase “headless browser” is used to describe Googlebot’s JavaScript capabilities. This just means Googlebot is a browser (Chrome) without the visual component. It does the same thing as Chrome, but instead of being designed to output visually and take user interactions, it’s designed to output code and to be interacted with via command line or code.
Search engines are using this capability to replicate browser functionality and to get at the code after JavaScript modifies it.
To make this super simple, you can think of a JavaScript crawl as Googlebot doing this:
- Google visits your webpage, as a browser
- At the load event (or after 5 seconds), they right click and select Inspect Element
- They select the HTML tag at the top
- They right click -> Copy -> Copy OuterHTML
- They use the copy and pasted HTML (the rendered content) just like they would use the HTML source
Let’s pause on that last point. Once Googlebot has the rendered content (Inspect Element HTML), it uses it like the traditional HTML source. This puts you back into your comfort zone of HTML and CSS.
The above process is also how you audit JavaScript-dependent sites for SEO.
This gives Google two HTML versions of the page. The pre-DOM HTML Source and the post-DOM rendered HTML. Generally, Google will use the rendered snapshot, but it may need to integrate signals between the two and deal with contradictions between the two.
When you look at the screenshot in Google’s Fetch and Render tool, what you are seeing is the rendering of the page around the time that Googlebot took the snapshot, using this rendered HTML and not the source HTML.
Importance of Events
There are two major event types to consider when looking at JavaScript SEO.
1) Load Event
The load event is fired when a page has fully loaded. Google has to take a snapshot of a page at some point and it may be around this point (some test show a 5 second timeout, but I believe they’re looking for ways to take it earlier to save resources). Of course, search engines can behave differently based on context. Content rendered after this point is not included in the JavaScript crawl snapshot and index of the page. This snapshot is the key, fundamental concept of dealing with JavaScript for SEO.
Think of it this way. A page modified by JavaScript can change continuously. Easy examples would be your inbox, Twitter feed, and Facebook feed. Search engines have to draw a line in the sand by taking a snapshot. You have to get the content in before they take the snapshot.
You can see this moment within Network Performance in Chrome Developer tools.
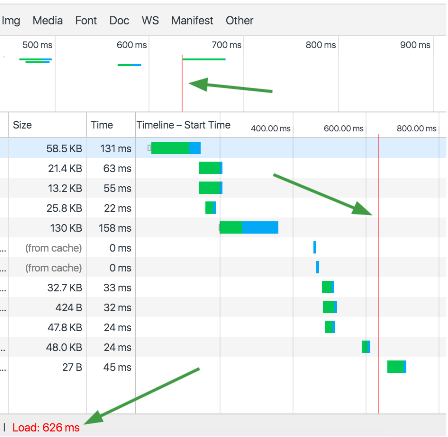
This tool shows a timeline of content loaded in the browser. The blue line denotes DOMContentLoaded event and the red line denotes the load event.
To summarize, content rendered to the page by this moment, when the snapshot of the rendered content is taken, should be indexed. Content not on the page by this moment should not be considered indexable. This even includes 3rd party community and rating/review tools. Delays in rendering 3rd party content can cause it to miss the snapshot, which causes the content to not be indexed.
You can also test this with the Fetch and Render tool. Content that comes in well after this point doesn’t appear in the screenshot.
2) User Events
Additionally, events can trigger after the load event that will make changes to the page. A common cause for these are user engagements, like tabbed content, forms, and interactive navigation. These are called user events. The most common is the onClick event.
In simple terms, a user’s mouse click will trigger an event in the browser called onClick. JavaScript can listen for these events and react to them, making changes to the page’s content based on the click.
Content that is dependent upon a user event generally does not get indexed. This new content is a permutation of a page’s content and should be considered non-canonical.
This means some content on a JavaScript rendered page is indexable, while other content is not. The title of a product page may be rendered by the snapshot, but those product attributes loaded in with AJAX on a hidden “tab” are not.
Confusing Bad SEO with JavaScript Limitations
Generally, if content is in by Google’s snapshot, it’s treated just like a traditional page. Of course, there are caveats and edge cases, but Google does a really good job at this.
While JavaScript rendering for search has its own inherent problems, and Google does have some issues dealing with it, most of the issues websites see are a result of implementation mistakes, not Google’s inability to deal with JavaScript.
Developers don’t always transfer traditional SEO best practices and requirements over when they build content with JavaScript. I do not understand why this happens, but once you point it out, most developers nail it moving forward. Once they get that the rendered HTML from the snapshot has to meet the same standards as a traditional page, many problems solve themselves.
Here are some of the common issues we see:
- Indexable URLs – Pages still need unique, distinct, and indexable URLs. A pushState does not a URL make. There needs to be a real page, with a 200 OK server response for each individual “page” you want to have indexed. A single page app needs to allow for server-side URLs for each category, article, or product.
- Getting pushState right – Use pushState to represent a URL change. However, this should represent the canonical URL that has server-side support. pushState mistakes and loose server-side implementation can create duplicate content.
- Missing page requirements – Pages still need: titles, meta descriptions, open graph, robots meta, clean URLs, alt attributes, etc. Audit a page using the Inspect Element approach. The same standards for HTML pages still apply to JavaScript-rendered content.
- ahref and img src – Pages still need links to them. Google’s crawl and discovery processes are, generally, the same. Put links in href attributes and images in src attributes. Google struggles with some various approaches, like putting URLs in data attributes instead of the typical HTML attribute.
- Multiple versions – JavaScript rendering can create versions (pre-DOM and post-DOM), so minimize contradictions between them. For example, HTML source has incorrect canonical and correct rel=next/prev, but the rendered page has the correct canonical and is lacking rel=next/prev.
- Bot Limitations – Several bots struggle with JavaScript crawling. To combat this, we recommend putting title, meta, social tags, and technical SEO tags in the server-side HTML source.
The 5 Core JavaScript SEO Rules
This boils down to 5 primary principles when optimizing JavaScript content (for Google):
- Content in by the load event (or 5 second timeout) is indexable.
- Content dependent on user events is not indexable.
- Pages require an indexable URL, with server-side support.
- Audit rendered HTML (Inspect Element) using the same SEO best practices you use on traditional pages.
- Avoid contradictions between versions.
These core principles will resolve nearly all questions and issues you’ll face when trying to get JavaScript content indexed and ranking in Google.
JavaScript implementations do have some risk. You’ll run into something that doesn’t work, requiring you to lean on your core principles and revise implementations until it works. You have to have some risk tolerance in implementing JavaScript. It also requires some acceptance of loss with other bots. However, it is possible to migrate an entire site from HTML to JS and maintain rankings/traffic. If you take your time and test, you can mitigate most risk.
This is by far the most informative article about JavaScript SEO. Now I have a better understanding of how Google bot reacts JavaScript when indexing. Thank you Briggsby. Is there any case study you can share?